The AI industry is currently trapped in a maze of its own making.
Silicon Valley is pouring billions of dollars into complex "Multi-Agent Orchestration" frameworks to babysit omnipotent, "God-Mode" AI agents that have a terrifying tendency to hallucinate and break enterprise databases. They are treating AI as if it is the application itself, rather than just another user interacting with the application.
At Code On Time, we took a different approach. We are a legacy Rapid Application Development (RAD) platform with over a decade of experience building the boring-but-critical plumbing of enterprise software: Role-Based Access Control (RBAC), Declarative Security, Web Application Firewalls, and database referential integrity.
It turns out that having this battle-tested IP is like owning a perfectly weighted hammer in a highly competitive field, only to discover that with minor adjustments, your specific hammer is actually perfect for brain surgery. By simply adding a deterministic State Machine and an asynchronous Heartbeat to our core framework, we didn't build a fragile AI wrapper. We invited the AI inside our existing fortress to act as a standard user—a Digital Co-Worker serving as the exact alter-ego of a specific human employee.
It executes the employee's prompt by navigating the application's REST Level 3 API (HATEOAS), which is strictly projected to that specific user's identity.
Mechanically, the built-in state machine passes the LLM the prompt's original goal (as the first item in the state_to_keep array) along with the current resource. It asks the LLM to pick the next hypermedia link that brings the goal closer to resolution, specify the reason "why," provide any optional payload for the link, and dictate what new information must be appended to the state_to_keep ledger. The state machine then physically fetches the links, updates the array, and manages the execution over multiple iterations until the goal is achieved.
To prove that our architecture is structurally sound and ready for enterprise data, we run it through a mental exercise we call The Fax Machine Test.
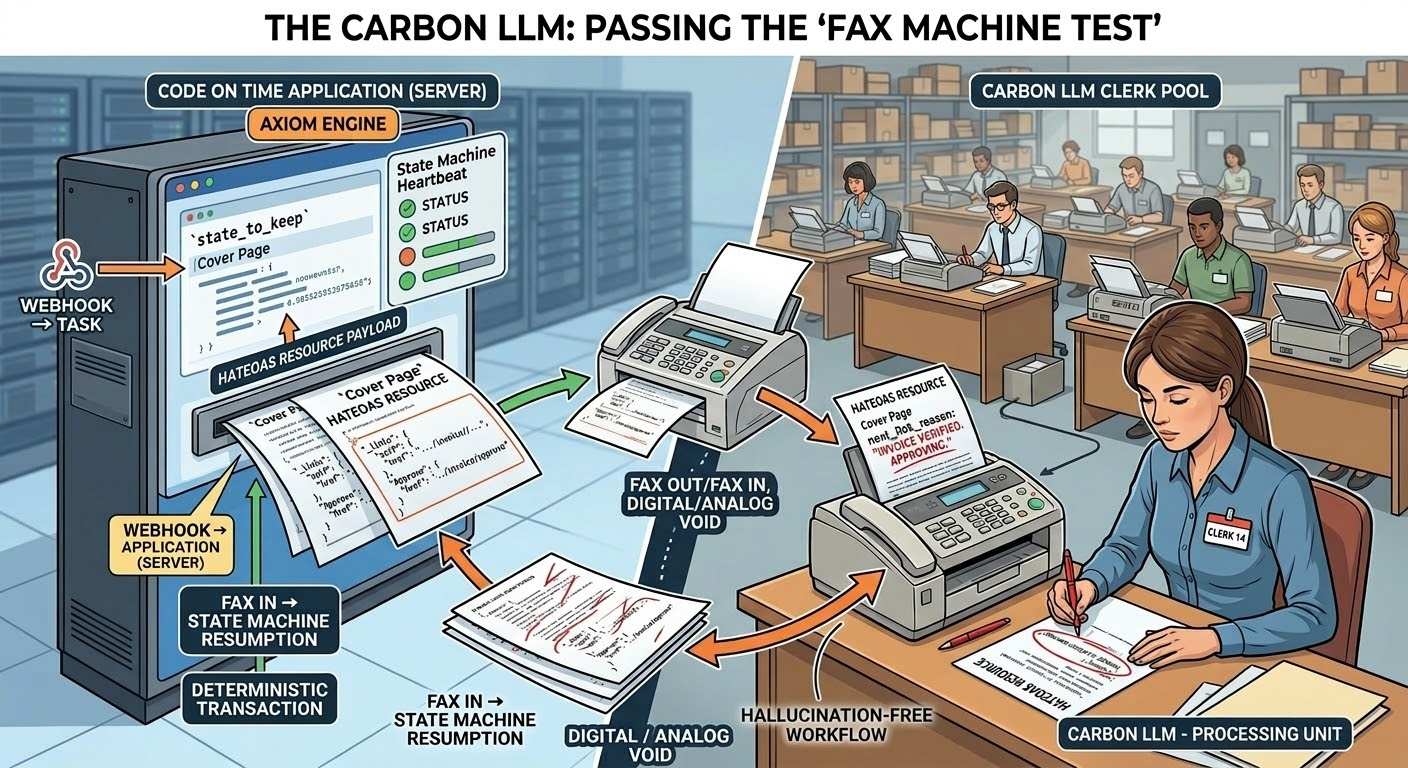
The GPU2027 Bug and the "Carbon LLM"
Imagine a scenario where the "GPU2027 bug" takes down every AI data center on earth, or the major AI providers suddenly raise their API prices by 10,000%. We are forced to fall back on a "Carbon LLM"—a warehouse full of human clerks sitting at desks with fax machines.
If your AI application relies on a SOTA (State of the Art) model to hold the context, execute the business logic, and orchestrate the workflow, your software ceases to exist the moment the servers go down.
Here is exactly what happens to the Digital Co-Worker running on our Axiom Engine: Absolutely nothing breaks. The state machine simply routes the iterations to the warehouse instead of an LLM. Here is how the asynchronous workflow plays out physically, step-by-step:
- The Goal Ledger (
state_to_keep array—a highly disciplined working memory ledger outlining the original objective and the exact steps taken so far.
- The Multiple-Choice Reality (HATEOAS): Following the cover page is the REST Level 3 HATEOAS resource. It shows the current state of the database record and a strict list of hypermedia links (controls). Crucially, it only includes the deterministic controls that this specific user's identity is authorized to click. Options that are illegal simply are not rendered.
- Entering the "Infer" State: The server prints the
state_to_keep and the HATEOAS resource onto paper. The Axiom Engine marks this prompt iteration as "infer" (signaling that it is waiting for an intelligence to process the data and make a decision) and drops it from the server's heartbeat. While it waits for the fax to be returned, the system consumes zero active compute resources.
- Carbon Inference: The fax machine transmits the paper to the "Carbon LLM" (the warehouse clerk pool). A human clerk reviews the goal ledger, analyzes the HATEOAS resource, and circles the most logical link to move toward the goal. They write their
next_link_reason on the page and fax it back.
- State Machine Resumption: The server receives the return fax. The human operator re-enters the clerk's written reason and specifies the selected link. This instantly updates the prompt iteration status from "infer" back to "next." The heartbeat instantly picks it back up, executes the deterministic transaction, and completes the loop.
The Infinite Context Window (Why We Don't Fax the Chat History)
Any AI engineer reading this is likely laughing. They are thinking: "If a user has been chatting with this AI for six months, are you going to fax a 10,000-page transcript of the conversation every time they ask a question?"
No. That is the "Context Window Trap" that is currently bleeding enterprise AI budgets dry. Most AI wrappers use a Transcript Model—they send the entire chat history to the LLM on every turn, requiring massive, expensive context windows.
Our architecture uses a State Model.
When a human user sends a new prompt to their Digital Co-Worker, the state machine does not append it to a massive chat log. Instead, the state machine starts iterating the next prompt directly on the last iterated HATEOAS resource of the previous prompt.
The "memory" of the conversation does not live in a bloated chat transcript; it lives in the physical state of the database. Because the LLM only ever receives the concise state_to_keep ledger and the current reality of the database record, the context window remains infinitely small and lightning-fast. The fax is never more than a few pages long, yet it creates the illusion of an infinite, multi-year conversation context.
Why the Fax Machine Test Matters
If an AI system cannot pass this test without requiring massive code rewrites, it is fundamentally brittle. By proving that our system works flawlessly with a human and a fax machine, we guarantee three critical advantages for the enterprise:
- Commoditized Intelligence: The LLM is not the "brain" of your application; it is simply a highly efficient processing unit. If models change, you swap the API key. The database rules, the security perimeter, and the workflow remain completely untouched.
- The Death of "God Mode" Agents: Because the HATEOAS resource physically removes links that the user's alter-ego doesn't have permissions for, the Carbon LLM (or the Silicon LLM) cannot hallucinate a destructive action. The options simply aren't on the paper.
- Native Asynchronous Reality: Enterprise work is slow. It requires approvals, context switching, and delays. Our architecture doesn't care if the inference takes 50 milliseconds from an AI or 15 minutes from a fax machine. The state machine handles both with zero idle compute waste.
The Invisible UI
Every database application created with Code On Time is already a multi-user system powered by a Visible UI (HTML). We realized that by replacing the HTML with Hypermedia JSON, we instantly created a multi-agent system powered by an Invisible UI.
You don't need to invent new, complex orchestration layers to keep AI in check. You don't need agents talking to other agents. You just need to hand the AI a standard user interface formatted for its eyes, and let your legacy database enforce the ACID rules just like it has for decades.